Créer ou mettre à jour des profils en masse
L'alimentation en masse des tables est possible à partir des APIs d'ACTITO. Celles-ci permettent un import de masse basés sur des fichiers zip contenant les données des profils. Le format attendu pour permettre le traitement de ces fichiers sera détaillé ci-dessous.
Les APIs permettent également de monitorer directement les imports, en récupérant son statut et les éventuelles causes d'erreur.
Import de profils en masse
Il existe une opération pour permettre l'import en masse de profils via les APIs publiques d'ACTITO : POST/entity/{e}/table{t}/import
Cet appel permet de pousser un fichier ZIP contenant un CSV reprenant les données de profils à charger.
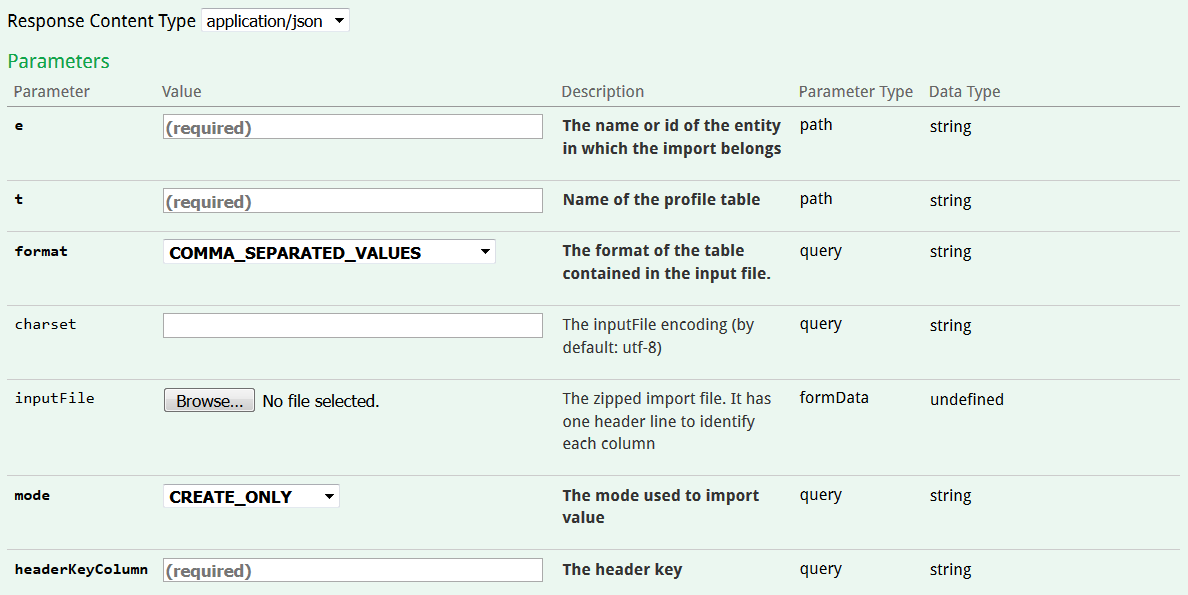
Les paramètres suivants doivent être renseignés :
-
Le nom de l'entité sur laquelle se trouve la table de profils
-
Le nom de la table de profils dans laquelle vous voulez importer des données
-
Le format du fichier CSV. 3 formats de fichier CSV sont supportés :
-
COMMA_SEPARATED_VALUES (séparateur : "," et retour à la ligne)
-
TAB_SEPARATED_VALUES (séparateur : indentation et retour à la ligne)
-
SEMI_COLON_SEPARATED_VALUES (séparateur : "; " et retour à la ligne)
-
-
"charset" : L'encodage du fichier CSV. Il s'agit d'UTF-8 par défaut.
-
Le mode d'import. Il y a 3 valeurs possibles :
-
CREATE_ONLY : ne charge les données que si elles ne correspondent à aucune ligne dans la table. En d’autres termes, la valeur de la ligne pour la "headerKeyColumn" indiquée ne doit pas exister en base.
-
UPDATE_ONLY : ne charge les données que si elles correspondent à un profil existant dans la table. Il s'agit uniquement d'une mise à jour de profils existants.
-
CREATE_UPDATE : Crée un profil si aucun ne correspond en base et le met à jour si le profil existe déjà.
-
-
"headerKeyColumn" : Nom de la colonne du fichier CSV à utiliser comme clé unique d’identification de la donnée. Cela doit correspondre à un champ unique de la table dans laquelle les données sont chargées.
Format du fichier
Le fichier sur lequel va se baser l'import doit être un fichier ZIP contenant un seul fichier CSV dans un format UTF-8.
Pour connaître le format du fichier propre à votre table de profil, vous pouvez vous aidez des opérations GET servant à obtenir la structure de votre table.
Format des colonnes
La première ligne du fichier doit correspondre au nom des colonnes (le header). Elle définit le nombre de colonnes du fichier.
Veuillez noter que :
-
Toutes les lignes du fichier doivent respecter le nombre de colonnes définies dans le header.
-
Deux colonnes ne peuvent pas posséder le même nom.
-
Toute colonne du header doit correspondre à la casse près au nom technique d’un champ de la table (attribut, abonnement ou segmentation) :
-
Il faut prévoir une colonne pour chaque abonnement. Un abonnement n’étant pas réellement un attribut de profil, le nom de la colonne doit suivre un format particulier :
"subscriptions#NomAbonnement" où NomAbonnement est le nom de l’abonnement. -
Il faut prévoir une colonne pour chaque segmentation. Une segmentation n’étant pas réellement un attribut de profil, la colonne doit suivre un format particulier :
"S_NomSegmentation" où NomSegmentation est le nom de la segmentation.
-
Les attributs multi-valeurs ne sont actuellement pas supportés.
Format des valeurs
Le format que doit prendre chacune valeur peut être obtenu en effectuant une requête GET pour récupérer la structure de la table de profil. Pour que le fichier soit valide, il est important de respecter les formats convenus, tels qu'ils sont définis ci-dessous :
Abonnements
La valeur attendue pour les abonnements est un Booléen dont les valeurs possibles sont : "true" et "false".
Segmentations simples
Dans le cas d'une segmentation simple, il convient d'indiquer "Member" si le profil doit appartenir à la segmentation, et de laisser la valeur vide s'il ne fait pas partie de la segmentation.
Segmentations exclusives
Dans le cas d’une segmentation exclusive, la valeur attendue est le nom du segment (sous-catégorie) dans lequel il faut insérer le profil. Si la segmentation n’est pas à partition complète, laissez la valeur vide pour indiquer qu’il ne faut mettre le profil dans aucune catégorie de la segmentation.
Date
Chaîne de caractères répondant à un des formats suivants :
YYYYMMDD
YYYY-MM-DD
dd/MM/yyyy
Moment
Chaîne de caractères répondant à un des formats suivants :
YYYYMMDD
YYYY-MM-DD
dd/MM/yyyy
YYYYMMDDhhmmss
YYYY-MM-DD hh:mm:ss
dd/MM/yyyy HH:mm:ss
MM/dd/yyyy hh:mm:ss AM|PM
Pays
Chaîne de caractères représentant le code à deux lettres ISO 3166-1 du pays, ou le nom anglais en minuscules.
Par exemple :
belgium ou BE
austria ou AT
algeria ou DZ
…
Langues
Chaîne de caractères représentant le code à deux lettres ISO 639-1 de la langue ou le nom anglais en minuscules.
Par exemple :
dutch ou NL
german ou DE
french ou FR
…
Genre
Valeurs possibles : M ou F
Astuce
Téléchargez un exemple de fichier CSV zippé d'import : ExempleFichierImportProfils.zip
Réponse à l'appel
Appel réussi
La réponse a un appel d'import réussi est l'identifiant technique de cet import.
Veuillez noter que le succès de l'appel n'implique pas forcément le succès de l'import. Il convient d'utiliser l'identifiant obtenu pour s'assurer que tous les profils ont bien été importés.
Erreurs lors de l'appel
Certaines erreurs sont renseignées directement dans la réponse à l'appel via une erreur 400.
Le corps de la réponse contiendra alors un code d'erreur propre qui complétera cette erreur générale. Il y a en effet plusieurs explications possibles :
-
"HEADER_NOT_FOUND_IN_ACTITO" : Les noms des colonnes de votre fichier CSV ne correspondent pas aux noms techniques exacts des attributs de votre base de données. Ceux-ci sont sensibles à la casse.
-
"NOT_FOUND" : Le champ renseigné comme "headerKeyColumn", c'est à dire la clé unique d'identification, n'est pas présente dans les noms des colonnes du fichier.
-
"INVALID_FIELD_VALUE" : Vous n'avez pas précisé de "headerKeyColumn" dans l'appel. Il est obligatoire de renseigner un attribut unique comme "headerKeyColumn", sauf si votre table possède une clé business auto générée.
Obtenir le statut et le résultat de l'import
Si l'appel est un succès, plusieurs opérations sont à votre disposition pour vérifier le bon déroulement de votre import. Elles sont détaillées sous la catégorie "import-controller".

L'opération GET/entity/{e}/import/{i}/status vous permettra d'obtenir le statut de l'import, c'est à dire si l'import est toujours en cours ou s'il est fini.
Il est pour cela nécessaire de renseigner l'entité sur laquelle a été créé l'import, ainsi que l'identifiant technique de l'import que vous avez obtenu en réponse à l'appel.
Il existe 3 statuts possibles :
-
RUNNING : L'import est en cours. Il faut attendre qu’il se termine.
-
FINISHED : L'import est terminé, le résultat est prêt (voir ci-dessous)
-
INERROR : L'import est tombé en erreur, il ne s’est pas fini proprement. C’est bien le job en entier qui tombe en erreur dans ce cas, pas une partie des données qui n’ont pu être importées. C'est uniquement le résultat de l'import qui vous indiquera si certaines lignes de données n'ont pas pu être importées.
L'opération GET/entity{e)/import{i}/result vous permettra d'obtenir le résultat de l'import, c'est à dire si l'import a bien pu être effectué dans sa totalité ou s'il y a des erreurs.
Les paramètres à renseigner sont également l'entité sur laquelle a été créé l'import, ainsi que l'identifiant technique de l'import que vous avez obtenu en réponse à l'appel.
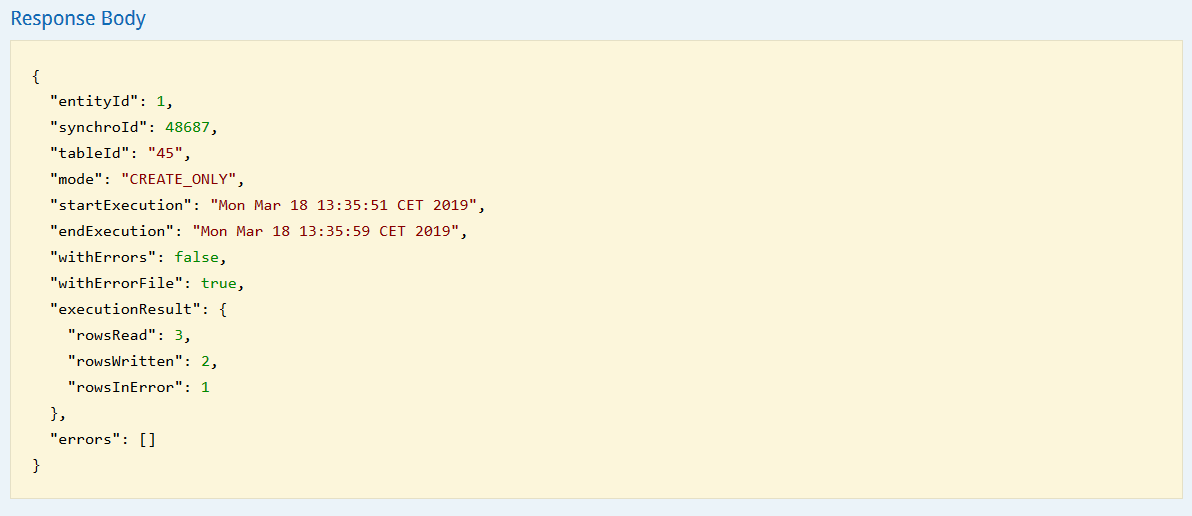
Le résultat obtenu vous indiquera d'une part :
-
L'identifiant technique de l'entité, de l'import et de la table de profils
-
Le mode de création
-
Le moment de début et de fin de l'exécution de l'import
D'autre part, les erreurs éventuelles seront renseignées grâce aux paramètres suivants :
-
"withErrors" : Booléen qui indique si l’exécution de l’import a connu une erreur globale. L’import n’a pas pu être exécuté et aucune donnée n’a été traitée.
-
"withErrorFile" : Booléen qui indique la présence d’un fichier d’erreur disponible pour téléchargement. Si le champ « withErrorFile » indique "true", le fichier a été traité mais des lignes n’ont pu être importées pour cause d’erreur de format ou d’intégrité. Toutes les lignes peuvent tomber en erreur sans pour autant que ça déclenche une erreur globale.
-
"executionResult": Résultat de l’exécution. Aura des données uniquement si il n'y a pas d'erreur globale
-
"rowsRead" : Nombre de lignes prises en considération à cette étape.
-
"rowsWritten" : Nombre de ligne écrites à cette étape et pour lesquelles l'import a donc été un succès.
-
"rowsInError" : Nombre de ligne non traitées pour cause d’erreur.
-
-
"errors" : Cette information ne sera disponible que s’il y a une erreur globale ayant empêché le traitement du fichier. Y sera renseignée la ligne ou colonne problématique.
Astuce
Le nombre de "rowsWritten" est le nombre d'entrées effectivement mises à jour ou créées. Les entrées déjà existantes ne sont pas prises en compte. De ce fait, le nombre de "rowsWritten" peut être moindre que le nombre de "rowsRead", même s'il n'y a pas d'erreur.
Résultat avec erreur globale
Une erreur globale implique une erreur liée au formatage du fichier plutôt qu'une erreur au niveau d'une ligne en particulier. Cependant, ce type d'erreur n'est pas assez flagrant que pour entraîner un échec de l'appel directement de la tentative de la création de l'import.
Une erreur globale est signalée dans le statut quand le paramètre "withErrors" est à "true". Un code d'erreur sera alors renseigné dans le paramètre "errors".
Il peut s'agit d'un des codes suivants :
-
"INVALID_LINES" : Une ligne est invalide, par exemple parce qu'elle a une colonne en trop
-
"DUPLICATE_HEADERS" : Un des noms de colonne du fichier est présent en double
Récupération du fichier d'erreurs
Si l'import n'est pas tombé en erreur globale mais que certaines lignes en particulier ne sont pas correctes, le paramètre "withErrorFile" sera renseigné comme "true".
Vous pourrez alors récupérer le détail de chaque erreur via un fichier. Pour cela, il existe l'opération GET/entity/{e}/import/{i}/errors
Les paramètres à renseigner sont l'entité sur laquelle a été créé l'import, ainsi que l'identifiant technique de l'import que vous avez obtenu en réponse à l'appel.
Astuce
Dans la documentation technique Swagger, obtenez plus facilement le fichier d'erreur en accédant à l'URL de requête sous la section "Request URL".
Vous obtiendrez un fichier ZIP nommé "resultImportId", où "ImportId" est l'identifiant technique de l'import que vous avez obtenu comme réponse lors de sa création.
Ce fichier ZIP contient un fichier d'erreur CSV reprenant telles quelles les lignes d’origine qui sont tombées en erreur mais avec 2 colonnes en plus :
-
"errorCode" : Il s'agit du code d’erreur, qui détaille la raison de l’erreur.
-
"errorColumn" : Ceci spécifie la colonne qui a posé problème.
Si plusieurs colonnes sont tombées en erreur pour la même ligne, cette ligne sera répétée une fois par erreur.
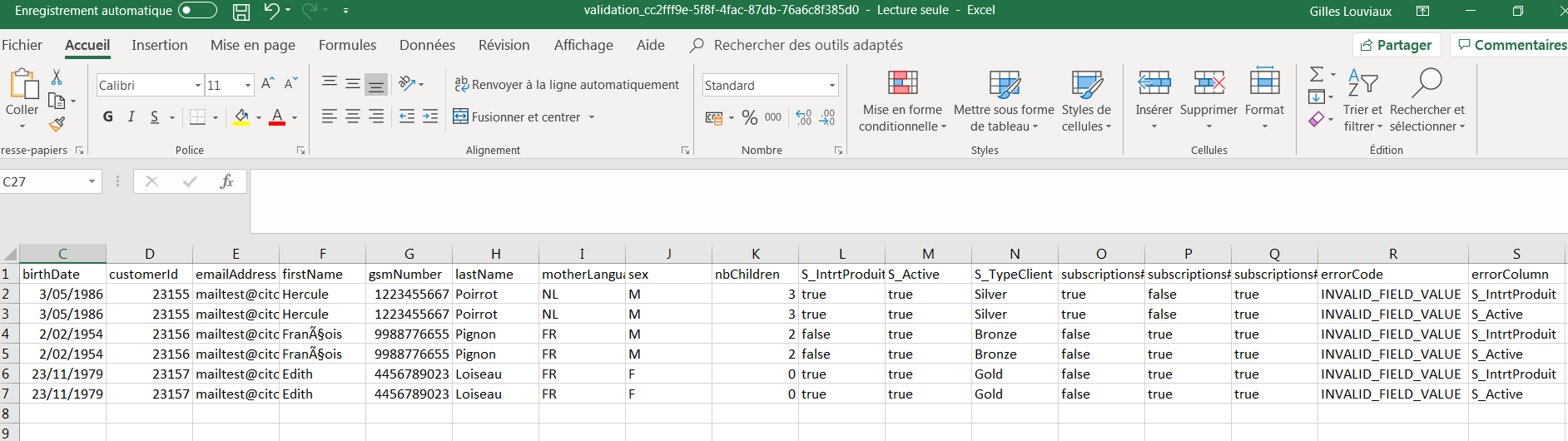
Dans notre exemple, on peut voir que 3 profils sont tombés en erreur pour cause de format de valeur invalide pour deux colonnes de segmentations. En effet, comme expliqué au point "Format des valeurs", dans le cas d'une segmentation simple, le format attendu est soit "Member", soit une cellule vide, pas un booléen true/false.
Exemple d'erreurs typiques
Les codes d'erreurs les plus fréquemment rencontrés dans un fichier d'erreur sont les suivants :
"INVALID_FIELD_VALUE" : La valeur de la ligne pour le champ indiqué dans "errorColumn" n’est pas valide, parce que le format est incompatible.
"DATA_ALREADY_EXISTS" : L’erreur survient car la donnée existe déjà dans la table. Cette erreur survient en mode "createOnly" lorsqu’une des lignes du fichier poussé réfère à une clé business qui existe déjà dans la table.
"UNKNOWN_DATA" : L’erreur survient car la donnée existe déjà dans la table. Cette erreur survient en mode "updateOnly" lorsqu’une des lignes du fichier poussé réfère à une clé business qui n’est pas présente dans la table.
"DUPLICATE_OBJECT" : L’erreur survient car le record à insérer contient une valeur déjà présente dans la base de données pour un attribut unique autre que la clé business.
"MISSING_FIELD_VALUE" : L’erreur survient car une valeur pour un attribut obligatoire est manquante.