Webservices liés aux tables
La notion de table personnalisée (ou "Custom Table") permet de modéliser l’activité (business) qui est propre à votre utilisation d'ACTITO. Ceci est possible grâce à un modèle de tables de données se rapportant directement ou indirectement à la table de profils, qui tient lieu d'élément central.
Dans une licence, il peut y avoir plusieurs tables spécifiques de nature et de structure différentes (par exemple : les offres, les commandes, les demandes de RDV, ... ).
Chacune de ces tables pourra être composée d’attributs permettant de stocker les informations nécessaires à la finalité de la table.
Pour plus d'information concernant le modèle de données et les tables personnalisées, nous vous invitons à vous référer au chapitre consacré au "Modèle de Données".
Les APIs de type CustomTable
Créer des tables personnalisées n'est pas possible via les APIs ACTITO. Celles-ci auront dû faire l'objet d'un projet de mise en place à la création de votre licence. Si votre activité nécessite la création d'une table personnalisée supplémentaire, il est nécessaire d'en faire préalablement la demande à votre gestionnaire de compte ou de projet.
La création de votre table est donc un prérequis pour pouvoir utiliser les APIs de type "CustomTable", qui permettent de gérer toutes les opérations en rapport avec les tables personnalisées.
De plus, il est recommandé que votre table contienne déjà au moins un enregistrement, afin de vous permettre d'identifier plus facilement la structure de la table et les éléments qui la composent.
D'une manière générale, le fonctionnement des APIs de type "CustomTable" est similaire à celui des APIs de profils. Ils permettent de :
Obtenir la structure d'une table
-
Obtenir des informations concernant les enregistrements des tables
-
Créer, mettre à jour et supprimer des enregistrements de tables
Obtenir la structure du modèle de données
Un modèle de données va typiquement être constitué de plusieurs tables de données personnalisées qui gravitent autour d'une table de profils.
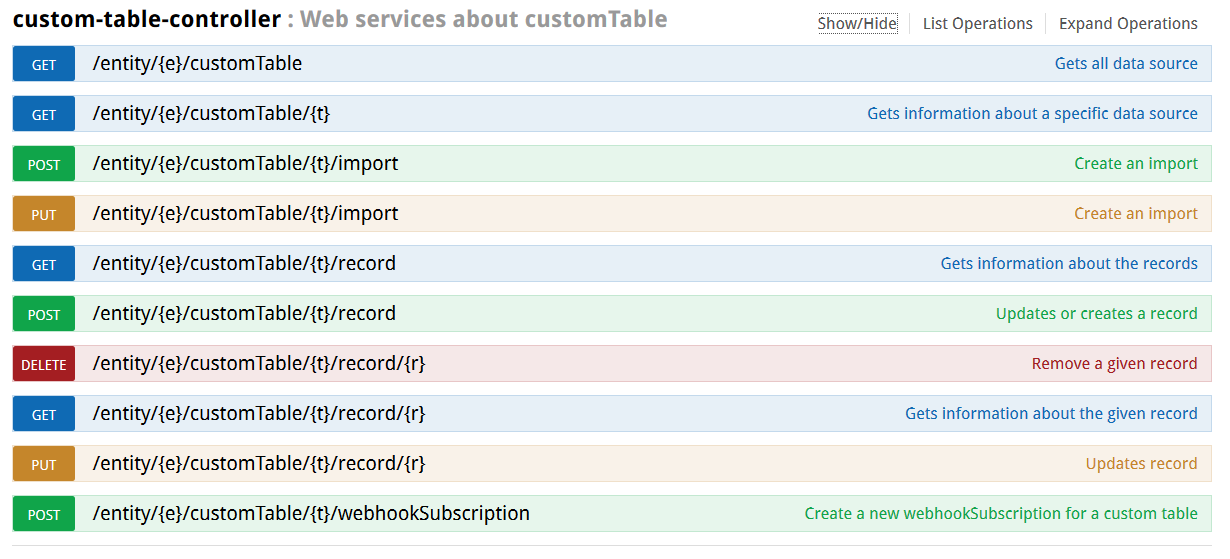
Vous pouvez obtenir la liste de toutes les tables
personnalisées enregistrées sur une entité
grâce à l'opération
GET/entity/{e}/customTable
Cette méthode vous donnera les caractéristiques des tables personnalisées liées à une entité et non à une table de profils en particulier.
Elle vous donnera les informations suivantes pour chaque table :
-
son identifiant technique auto-généré, qui peut être utilisé pour appeler et soumettre des données
-
son nom technique, qui peut être utilisé pour appeler et soumettre des données
-
son nom d'affichage, tel qu'il apparaît dans ACTITO
-
sa catégorie : lecture uniquement ou lecture et modification
-
les capacités de la table (capabilities) : Pour davantage d'information à ce sujet, voir "Comprendre les capacités des tables"
Obtenir la structure d'une table
ACTITO vous donne la possibilité de définir le contenu de vos tables personnalisées durant leur mise en place, afin de s'adapter aux besoins spécifiques de votre activité.
Une fois créée dans ACTITO, la table personnalisée sera caractérisée par :
-
Un nom "t", par exemple, "DemoDocTickets"
-
Une entité "e", qui correspond aux droits d'accès. Dans cet exemple : "actito"
Vous pouvez utiliser l'opération GET/entity/{e}/customTable pour obtenir la structure de cette table.
Ceci vous permettra de comprendre comment la structure de votre table se traduit dans l'API. Grâce à cette information, vous pourrez plus facilement programmer des méthodes POST ou PUT pour créer un import de données en utilisant correctement tous les éléments qui constituent votre table personnalisée.
Pour ce faire, entrez le nom de l'entité et de la table comme paramètres.
Astuce
La casse n'est pas prise en compte au niveau des noms.
Exemple de réponse à cette requête : (Téléchargez cet exemple)
Curl callcurl -X GET --header "Accept: application/json" https://test.actito.be/ActitoWebServices/ws/v4/entity/actito/customTable/demodoctickets
Response body
{ "id": "daf01958-fef1-43fe-a921-12d82772dc2a",
"entityId": 1,
"technicalName": "DemoDocTickets",
"userName": "DemoDocTickets",
"category": "READWRITE",
"capabilities": [
"INTERACTION",
"EVENT_GENERATED_TABLE"
], "attributes": [
{ "fieldName": "ref",
"type": "Long",
"unique": true,
"required": true,
"description": null
}, { "fieldName": "refMagasin",
"type": "String",
"unique": false,
"required": true,
"description": null
}, { "fieldName": "montant",
"type": "Long",
"unique": false,
"required": true,
"description": null
}, { "fieldName": "customerId",
"type": "Long",
"unique": false,
"required": true,
"description": null
}, { "fieldName": "updateMoment",
"type": "Date",
"unique": false,
"required": true,
"description": null
}, { "fieldName": "creationMoment",
"type": "Date",
"unique": false,
"required": true,
"description": null
}, { "fieldName": "id",
"type": "Long",
"unique": true,
"required": true,
"description": null
} ], "primaryKey": "id",
"businessKey": "ref",
"creationMoment": "2019-02-25T16:19:08+00:00",
"updateMoment": "2019-02-26T08:41:56+00:00"
}Cette réponse se caractérise par :
-
Des informations sur le type de tables concerné
-
La liste de attributs et de leurs caractéristiques :
-
"fieldName" est le nom technique du champ, qui devra être utilisé pour pousser des données
-
"type" : Le type de champ attendu
-
"unique" : Si l'attribut est unique ou pas
-
"required" : Si l'attribut est obligatoire ou pas
-
"description" : La description de l'attribut
-
-
Les informations techniques liées à la table :
-
"primaryKey" : il s'agit de l'identifiant technique de la table, qui correspondra toujours à un attribut technique appelé "id" et auto-généré. Cet attribut technique permet d'identifier chaque enregistrement de la table. Ce champ ne devra jamais être spécifié dans vos appels pour pousser des données.
-
"businessKey" : il s'agit de la clé business de la table. Elle servira d'identifiant clé pour identifier chaque enregistrement lors de vos appels pour pousser des données. Elle devra donc toujours y être mentionnée.
-
"creationMoment" et "updateMoment" : il s'agit du moment de création et de mise à jour de la table. Ce champ technique ne devra jamais être spécifié dans vos appels.
-
Obtenir des informations sur des enregistrements
Obtenir les informations d'un enregistrement spécifique
Il peut être utile d'obtenir des informations à propos des enregistrements qui sont déjà présents dans votre table. Cela vous donnera un exemple concret des informations qui sont attendues lors des appels de création de données, surtout en ce qui concerne les caractéristiques des attributs qui la composent.
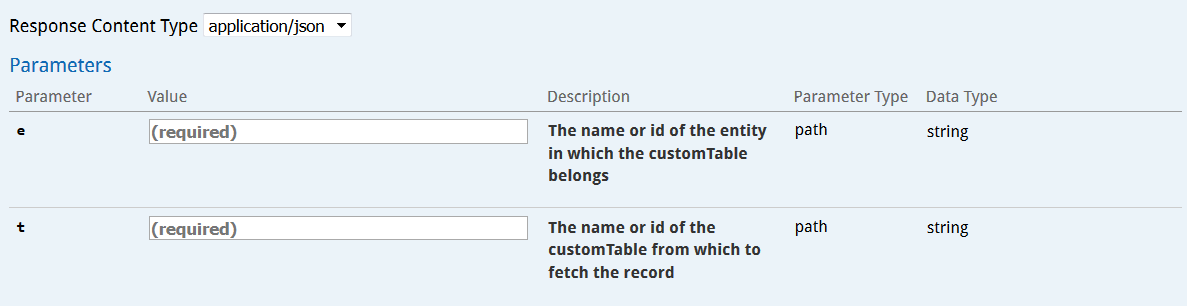
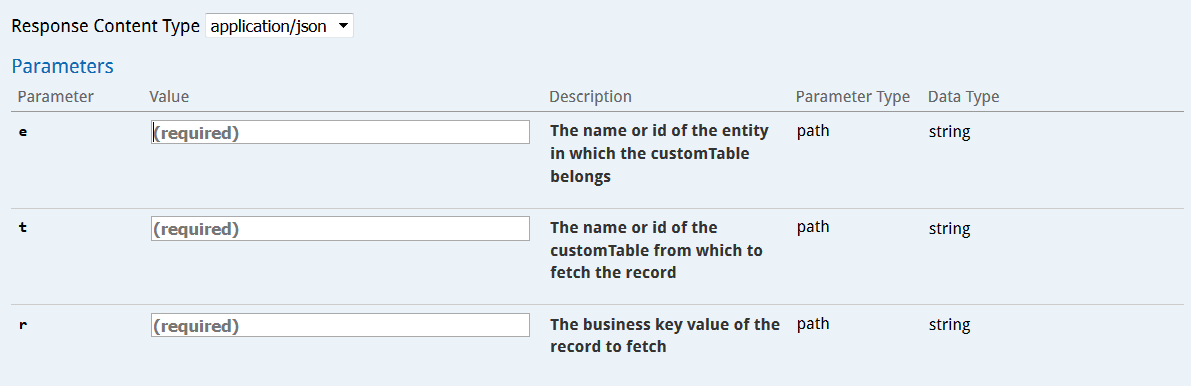
Vous pouvez récupérer les détails concernant un enregistrement via l'opération GET/entity/{e}/customTable/{t}/record/{r)
Les paramètres à renseigner sont les suivants :
-
l'entité à laquelle appartient la table personnalisée
-
la table personnalisée qui contient l'enregistrement
-
l'enregistrement à récupérer : il faut pour cela utiliser sa clé business, telle que vous avez pu l'identifier en obtenant la structure de la table. L'identifiant technique automatiquement généré ne peut pas être utilisé ici.
Exemple de résultat pour cette requête : (Téléchargez cet exemple)
Curl callcurl -X GET --header "Accept: application/json" "https://test.actito.be/ActitoWebServices/ws/v4/entity/actito/customTable/demodoctickets/record/32"
Response body
{ "properties": [
{ "name": "ref",
"value": 32
}, { "name": "updateMoment",
"value": "2019-02-25T17:26:44+01:00"
}, { "name": "creationMoment",
"value": "2019-02-25T17:26:44+01:00"
}, { "name": "customerId",
"value": 25716
}, { "name": "montant",
"value": 123
}, { "name": "id",
"value": 31
}, { "name": "refMagasin",
"value": "5"
} ], "businessKey": "32"
}Veuillez noter que certains attributs techniques sont automatiquement renseignés dans la réponse. Ces attributs ne sont pas modifiables. Il s'agit de :
-
"id" : l'identifiant technique auto-généré
-
"creationMoment" : la date et l'heure de création
-
"updateMoment" : la date et l'heure de la dernière mise à jour
Obtenir les informations d'enregistrements sur base d'une recherche
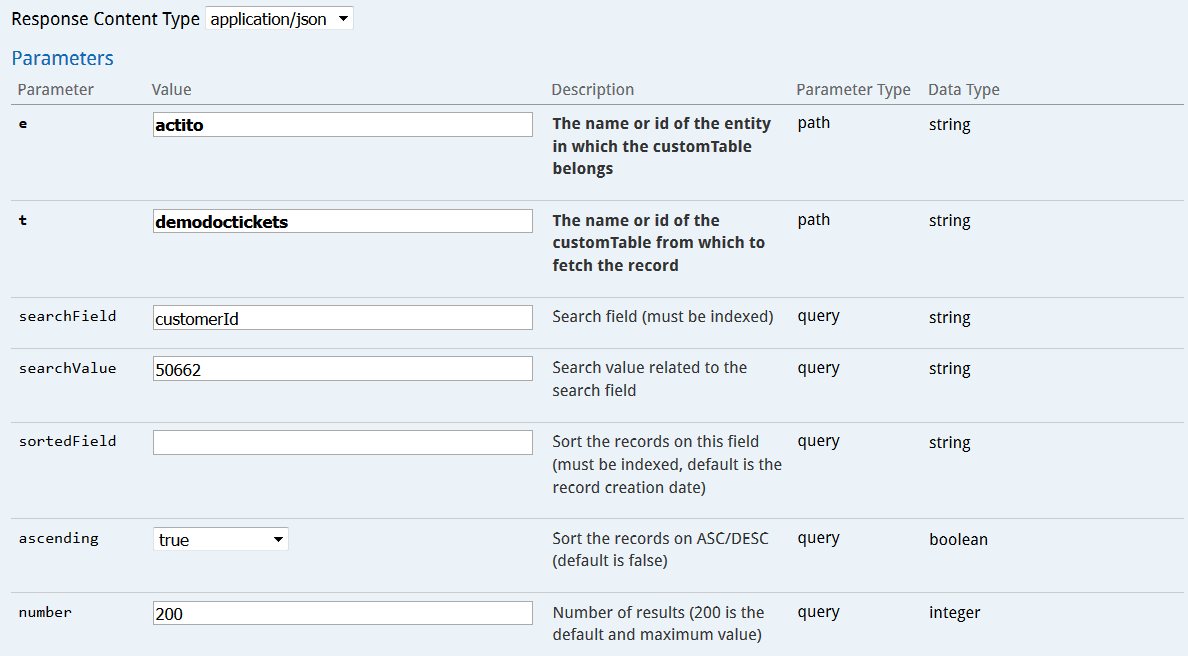
L'opération GET/entity/{e}/customTable/{t}/record vous permettra d'obtenir les informations d'enregistrements en ajoutant des paramètres de requête spécifiques. Par exemple, obtenir tous les tickets d'un client en particulier.
Il nécessaire de renseigner l'entité et la table personnalisée concernée. Vous pouvez ensuite spécifier les paramètres de requête suivants :
-
"searchField" : il s'agit du nom technique du champ sur lequel la recherche doit être basée. Ce champ doit être indexé.
-
"searchValue" : renseignez la valeur pour le champ de recherche pour laquelle vous voulez obtenir tous les enregistrements. Il s'agit d'un critère de stricte égalité.
-
"sortedField" : renseignez le champ utilisé pour déterminer l'ordre dans lequel tous les enregistrements vont être présentés. Par défaut, il s'agit de la date de création. Ce champ doit être indexé.
-
"ascending" : choisissez si les enregistrements doivent être présentés en ordre croissant (true) ou décroissant (false).
-
"number" : choisissez le nombre d'enregistrements à afficher (la valeur maximum et par défaut est de 200).
Exemple de réponse à une requête basée sur une recherche par numéro de client : GET/entity/{e}/customTable/{t}/record.docx
Curl callcurl -X GET --header "Accept: application/json" "https://test.actito.be/ActitoWebServices/ws/v4/entity/actito/customTable/demodoctickets/record?searchField=customerId&searchValue=50662&sortedField=creationMoment&ascending=true&number=200"
Response body
{ "records": [
{ "properties": [
{ "name": "ref",
"value": 49
}, { "name": "updateMoment",
"value": "2019-02-25T17:26:44+01:00"
}, { "name": "creationMoment",
"value": "2019-02-25T17:26:44+01:00"
}, { "name": "customerId",
"value": 50662
}, { "name": "montant",
"value": 143
}, { "name": "id",
"value": 39
}, { "name": "refMagasin",
"value": "3"
} ], "businessKey": 49
}, { "properties": [
{ "name": "ref",
"value": 4
}, { "name": "updateMoment",
"value": "2019-02-25T17:26:44+01:00"
}, { "name": "creationMoment",
"value": "2019-02-25T17:26:44+01:00"
}, { "name": "customerId",
"value": 50662
}, { "name": "montant",
"value": 36
}, { "name": "id",
"value": 40
}, { "name": "refMagasin",
"value": "2"
} ], "businessKey": 4
}, { "properties": [
{ "name": "ref",
"value": 6
}, { "name": "updateMoment",
"value": "2019-02-25T17:26:44+01:00"
}, { "name": "creationMoment",
"value": "2019-02-25T17:26:44+01:00"
}, { "name": "customerId",
"value": 50662
}, { "name": "montant",
"value": 30
}, { "name": "id",
"value": 41
}, { "name": "refMagasin",
"value": "5"
} ], "businessKey": 6
}, { "properties": [
{ "name": "ref",
"value": 7
}, { "name": "updateMoment",
"value": "2019-02-25T17:26:44+01:00"
}, { "name": "creationMoment",
"value": "2019-02-25T17:26:44+01:00"
}, { "name": "customerId",
"value": 50662
}, { "name": "montant",
"value": 75
}, { "name": "id",
"value": 42
}, { "name": "refMagasin",
"value": "4"
} ], "businessKey": 7
}, { "properties": [
{ "name": "ref",
"value": 19
}, { "name": "updateMoment",
"value": "2019-02-25T17:26:44+01:00"
}, { "name": "creationMoment",
"value": "2019-02-25T17:26:44+01:00"
}, { "name": "customerId",
"value": 50662
}, { "name": "montant",
"value": 18
}, { "name": "id",
"value": 43
}, { "name": "refMagasin",
"value": "1"
} ], "businessKey": 19
} ]}Créer et mettre à jour des enregistrements dans une table
La création et la mise à jour des tables personnalisées fonctionne de manière très similaire aux mêmes opérations pour les tables de profils. Il convient donc faire un choix entre les deux manières créer ou mettre à jour des enregistrements dans une table personnalisée : un par un ou par lots. Le choix entre ces deux manières de procéder doit être fait à la fois par rapport aux besoins propres à votre activité, mais aussi par rapport aux limites à respecter concernant l'utilisation des webservices.
Il convient donc de se poser les questions suivantes :
-
Une synchronisation en temps réel est-elle nécessaire ?
-
Avez-vous pour but de déclencher des scénarios en temps réel ?
-
Quels sont les volumes à traiter ?
-
La méthode de votre choix est-elle compatible avec les limites d'utilisation ?
Les APIs d'import de masse doivent être utilisés quand les données peuvent être accumulées jusqu'à atteindre un volume suffisant pour un traitement par lots. La méthode d'import de masse n'a pas pour vocation de pousser de façon fréquentes des fichiers légers qui ne contiennent de quelques enregistrements. En effet, la limite est de 12 appels de masse par jour. De plus, les imports de masse sont asynchrones. Pousser plusieurs fichiers en même temps n'est pas une pratique convenue, étant donné qu'ils ne seront considérés que l'un à la suite de l'autre.
Par contre, quand les données sont utilisées pour déclencher un processus de travail ou qu'elles doivent être synchronisées de façon immédiate vers une base de données, il est préférable d'utiliser les appels un par un.
Si les spécificités de votre activité présentent un cas mixte de besoin de synchronisations en temps réel et de synchronisation journalière, il est conseillé de répartit les appels entre les imports de masse et les appels un par un au cas par cas selon les besoins de volume et d'immédiateté.
Créer ou mettre à jour un seul enregistrement
Les appels un par un sont à privilégier quand les données sont utilisées pour déclencher un processus de travail ou qu'elles doivent être synchronisées de façon immédiate vers une base de données.
Il est possible de créer ou de mettre à jour un enregistrement d'une table personnalisée grâce à l'opération POST/entity{e}/customTable{t}/record
Cette méthode implique l’utilisation de code JSON pour saisir les données correspondant à l'enregistrement concerné. Il est donc conseillé de s'être familiarisé avec la structure de la base de données auparavant, comme expliqué au début de cette page.
Les paramètres à renseigner sont les suivants :
-
l'entité à laquelle la table appartient
-
le nom de la table personnalisée à laquelle l'enregistrement doit être ajouté, ou celle où se trouve l'enregistrement qui doit être mis à jour
-
"allowUpdate" : Ceci permet de choisir si vous voulez mettre à jour un enregistrement s'il existe déjà. En effet, POST est avant tout une méthode de création, mais elle peut être utilisée pour les mises à jour
-
"record" : Les propriétés de l'enregistrement concerné, sous forme de code JSON à insérer. Le schéma sur la droite vous donne un modèle de la structure de ce code. Il s'agit d'un tableau de valeurs reprenant les paires de noms techniques des propriétés ("name") et de la valeur qu'elles doivent prendre ("value")
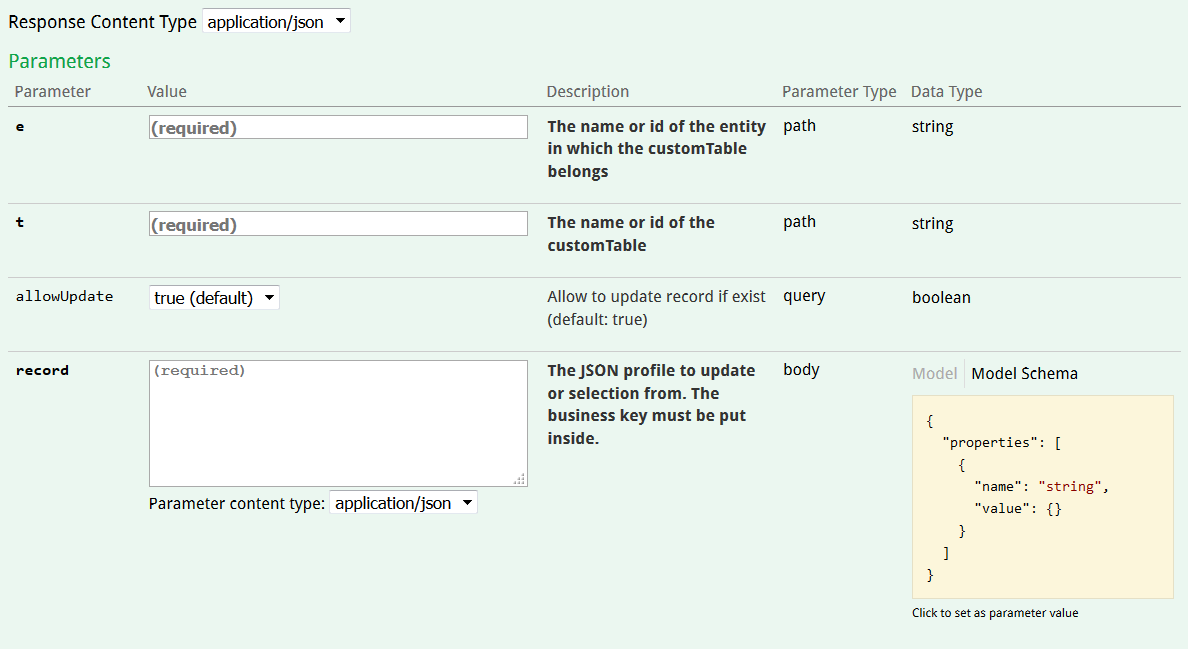
Exemple de requête incluant le code JSON à pousser dans le paramètre "record" : POST/entity/{e}customTable{t}record.docx
Curl callcurl -X POST --header "Content-Type: application/json" --header "Accept: application/json" -d "{
\"properties\": [{
\"name\": \"ref\",
\"value\": \"185\"
}, { \"name\": \"refMagasin\",
\"value\": \"2\"
}, { \"name\": \"montant\",
\"value\": \"93\"
}, { \"name\": \"customerId\",
\"value\": \"34567\"
} ]}" "https://test.actito.be/ActitoWebServices/ws/v4/entity/actito/customTable/demodoctickets/record?allowUpdate=true"
Response body
{ "businessKey": 185
}La réponse sera tout simplement la clé business ("businessKey") de l'enregistrement que vous venez de créer ou de mettre à jour.
Créer ou mettre à jour des enregistrements en masse
L'alimentation en masse des tables est possible à partir des APIs d'ACTITO. Celles-ci permettent un import de masse basés sur des fichiers ZIP contenant les données de tables. Le fonctionnement des imports de données en masse dans les tables personnalisées est exactement le même pour les imports en masse de profils.
Pour davantage d'information concernant le format attendu pour le fichier, le résultat de l'import ou les erreurs éventuelles que vous pouvez rencontrer, nous vous invitons à vous référer à la page consacrée à l'import en masse de profils.
Les APIs publiques d'ACTITO permettent l'import en masse d'enregistrement de tables personnalisées via l'opération POST/entity/{e}/customTable{t}/import
Cet appel permet de pousser un fichier ZIP contenant un CSV reprenant les données de table à charger.
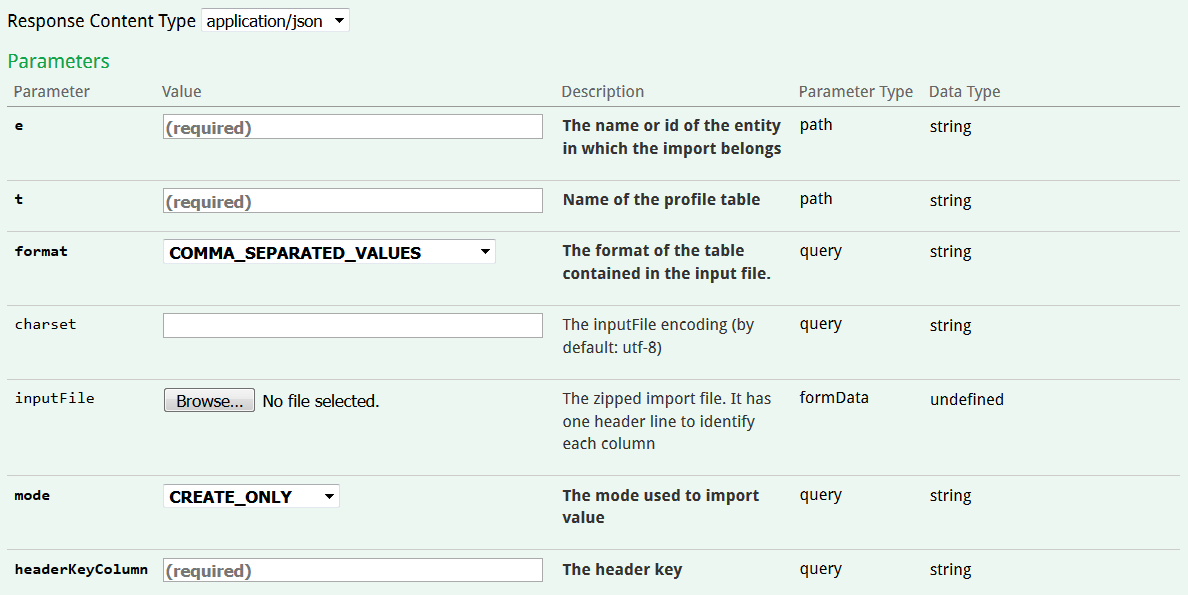
Les paramètres suivants doivent être renseignés :
-
le nom de l'entité sur laquelle se trouve la table de profils
-
le nom de la table personnalisée dans laquelle vous voulez importer des données
-
le format du fichier CSV. 3 formats de fichier CSV sont supportés :
-
COMMA_SEPARATED_VALUES (séparateur : "," et retour à la ligne)
-
TAB_SEPARATED_VALUES (séparateur : indentation et retour à la ligne)
-
SEMI_COLON_SEPARATED_VALUES (séparateur : "; " et retour à la ligne)
-
-
"charset" : l'encodage du fichier CSV. Il s'agit d'UTF-8 par défaut.
-
le mode d'import. Il y a 3 valeurs possibles :
-
CREATE_ONLY : ne charge les données que si elles ne correspondent à aucune ligne dans la table. En d’autres termes, la valeur de la ligne pour la headerKeyColumn indiquée ne doit pas exister en base.
-
UPDATE_ONLY : ne charge les données que si elles correspondent à un profil existant dans la table. Il s'agit uniquement d'une mise à jour de profils existants.
-
CREATE_UPDATE : Crée un profil si aucun ne correspond en base et le met à jour si le profil existe déjà.
-
-
"headerKeyColumn" : nom de la colonne du fichier CSV à utiliser comme clé unique d’identification de la donnée. Cela doit correspondre à un champ unique de la table dans laquelle les données sont chargées.
Astuce
Téléchargez un exemple de fichier CSV zippé pour un import de table personnalisée en masse: DocImportCustomTable.zip
Après avoir lancé votre import, un code 200 indiquera le succès de l'appel webservice. Le corps de réponse vous donnera alors l'identifiant technique de cet import.
Cet identifiant technique pourra être utilisé pour obtenir le statut de l'import et d'identifier les éventuelles erreurs, comme expliqué sur la page consacrée aux imports en masse de profils.